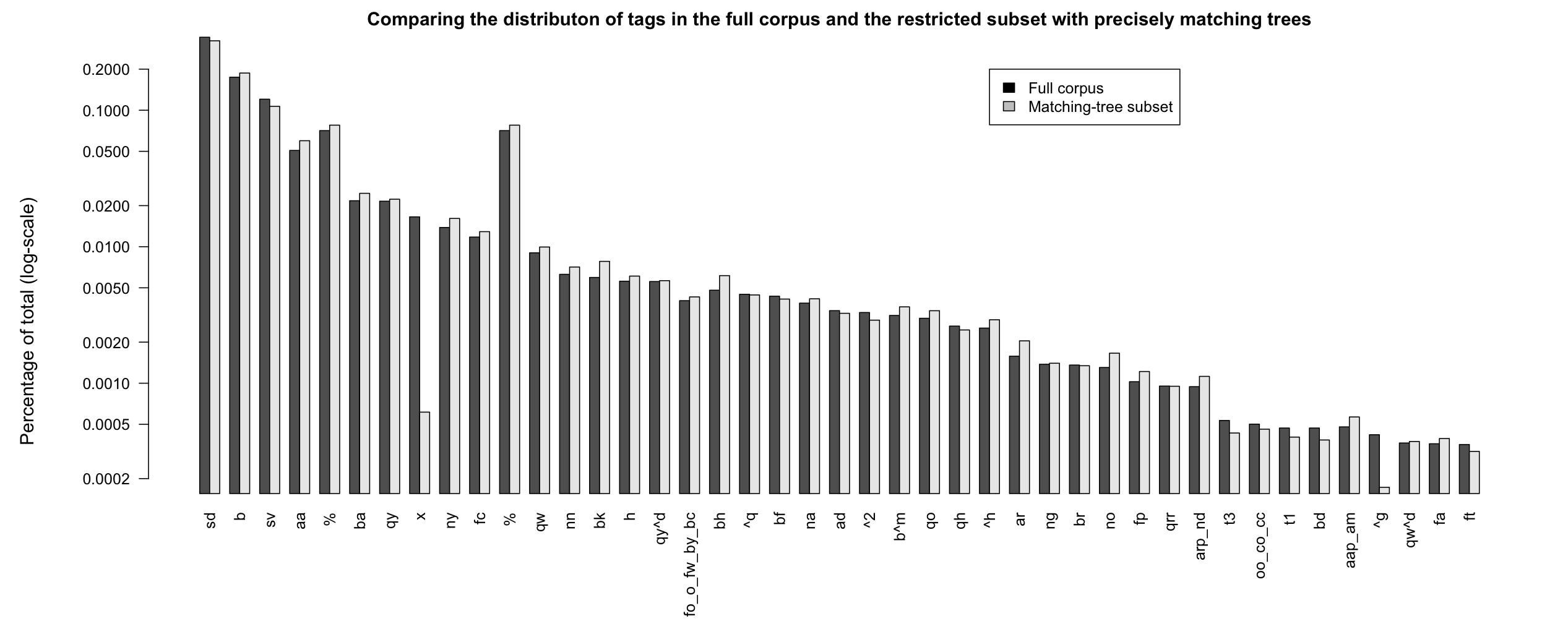
Figure PERCOMPARE
Comparing percentages of tags for the full corpus and the
restricted subset that have single, precisely matching trees.
The Switchboard Dialog Act Corpus (SwDA) extends the Switchboard-1 Telephone Speech Corpus, Release 2, with turn/utterance-level dialog-act tags. The tags summarize syntactic, semantic, and pragmatic information about the associated turn. The SwDA project was undertaken at UC Boulder in the late 1990s.
Recommended reading:
Note: Here is updated SwDA code that is Python 2/3 compatible. It is recommended over the code below.
Code and data:
The SDA trascripts are a free download:
The files are human-readable text files with lines like this:
b B.22 utt1: Uh-huh. /
sd A.23 utt1: I work off and on just temporarily and usually find friends to babysit, /
sd A.23 utt2: {C but } I don't envy anybody who's in that <laughter> situation to find day care. /
b B.24 utt1: Yeah. /
It's worth unpacking the archive file and opening up a few of the transcripts to get a feel for what they are like.
The SwDA is not inherently linked to the Penn Treebank 3 parses of Switchboard, and it is far from straightforward to align the two resources Calhoun et al. 2010, §2.4. In addition, the SwDA is not distributed with the Switchboard's tables of metadata about the conversations and their participants. I'd like us to have easy access to all this information, so I created a version of the corpus that pools all of this information to the best of my ability:
When you unpack swda.zip, you get a directory with the same basic structure as that of swb1_dialogact_annot.tar.gz. The file swda-metadata.csv contains the transcript and caller metadata for this subset of the Switchboard.
The format for all the transcript files is the same. I describe the column values below, in the context of the Python code I wrote for us to work with this corpus.
The Python classes:
The code's Transcript objects model the individual files in the corpus. A Transcript object is built from a transcript filename and the corpus metadata file:
Transcript objects have the following attributes:
| Attribute name | Object type | Value |
|---|---|---|
| ptb_basename | str | The filename: directory/basename |
| conversation_no | int | The numerical conversation Id. |
| talk_day | datetime | with methods like month, year, ... |
| topic_description | str | short description |
| length | int | in seconds |
| prompt | str | long decription/query/instruction |
| from_caller_no | int | The numerical Id of the from (A) caller |
| from_caller_sex | str | MALE, FEMALE |
| from_caller_education | int | 0, 1, 2, 3, 9 |
| from_caller_birth_year | datetime | YYYY |
| from_caller_dialect_area | str | MIXED, NEW ENGLAND, NORTH MIDLAND, NORTHERN, NYC, SOUTH MIDLAND, SOUTHERN, UNK, WESTERN |
| to_caller_no | int | The numerical Id of the to (B) caller |
| to_caller_sex | str | MALE, FEMALE |
| to_caller_education | int | 0, 1, 2, 3, 9 |
| to_caller_birth_year | datetime | YYYY |
| to_caller_dialect_area | str | MIXED, NEW ENGLAND, NORTH MIDLAND, NORTHERN, NYC, SOUTH MIDLAND, SOUTHERN, UNK, WESTERN |
| utterances | list | A list of Utterance objects. |
The attributes permit easy access to the properties of transcripts. Continuing the above:
The utterances attribute of Transcript objects is the list of Utterance objects for that corpus, in the order in which they appear in the original transcripts.
Utterance objects have the following attributes:
| Attribute | Object type | Value |
|---|---|---|
| caller | str | A, B, @A, @B, @@A, @@B |
| caller_no | int | The caller Id. |
| caller_sex | str | MALE or FEMALE |
| caller_education | str | 0, 1, 2, 3, 9 |
| caller_birth_year | int | 4-digit year |
| caller_dialect_area | str | MIXED, NEW ENGLAND, NORTH MIDLAND, NORTHERN, NYC, SOUTH MIDLAND, SOUTHERN, UNK, WESTERN |
| transcript_index | int | line number relative to the whole transcript |
| utterance_index | int | Utterance number (can span multiple TranscriptIndex numbers) |
| subutterance_Index | int | Utterances can be broken across line. This gives the internal position. |
| tag | list | strings; see below |
| text | str | the text of the utterance |
| pos | str | the part-of-speech tagged portion of the utterance |
| trees | nltk.tree.Tree | the parse of Text; see below for discussion |
Assuming you still have your Python interpreter open and the trans instance set as before, you can continue with code like the following:
Perhaps the most noteworthy attribute is utt.trees. This is always a set of nltk.tree.Tree objects (sometimes an empty set, because only a subset of the Switchboard was parsed). For our utt instance, there is just one tree, and it properly contains the actual utterance content. In this case, the rest of the tree occurs two lines later, because speaker A interrupts:
Cautionary note: Because the trees often properly contain the utterance, they cannot be used to gather word- or phrase-level statistics unless care is taken to restrict attention to the subtrees, or fragments thereof, that represent the utterance itself. For additional discussion, see the Penn Discourse Treebank 3 Trees section below.
The main interface provided by swda.py is the CorpusReader, which allows you to iterate through the entire corpus, gathering information as you go. CorpusReader objects are built from just the root of the directory containing your csv files. (It assumes that swda-metadata.csv is in the first directory below that root.)
The two central methods for CorpusReader objects are iter_transcripts() and iter_utterances().
Here's a function that uses iter_transcripts() to gather information relating education levels and dialect areas:
The method iter_utterances() is basically an abbreviation of the following nested loop:
The following code uses iter_utterances() to drill right down to the utterances to count the raw tags:
The output is a list that is very much like the one under "Finally, for reference, here are the original 226 tags" at the Coders' Manual page. (I don't know why the counts differ slightly from the ones given there. I tried many variations — adding/removing * or @ from the tags; adding/removing a hard-to-detect nameless file in the distribution repeating sw09utt/sw_0904_2767.utt, etc., but I was never able to reproduce the counts exactly.)
It is possible to work with our SwDA CSV-based distribution using a program like Excel or R. The following code shows how to read in the CSV files and work with them a bit in R:
We can also read in the metadata and relate an utterance to it via the conversation_no value:
In principle, this could be every bit as useful as the Python classes. Indeed, there are advantages to working with data in tabular/database format, as opposed to constantly looping through all the files. However, if you take this route, you'll have to write your own methods for dealing with the special values for trees, tags, dates, and so forth. I think Python is ultimately a better tool for grappling with the diverse information in the SwDA.
I now briefly review the special annotations of this subset of the Switchboard: the act tags, the POS annotations, and the parsetrees.
There are over 200 tags in the corpus. The Coders' Manual defines a system for collapsing them down to 44 tags. (They say 42; I am not sure what they do with 'x', and their table has 43 rows, so it might be that 42 is just a minor miscount.)
The Utterance object method damsl_act_tag() converts the original tags to this 44 member subset:
The tags are the main addition to the corpus. Here is the table of training-set stats from the Coders' Manual extended with a column giving the total counts for the entire corpus, using damsl_act_tag().
Eva Khatchadourian never wanted to be a mother. Her son Kevin, from infancy, seems to sense her ambivalence and becomes a sociopath, eventually committing a school massacre. The novel is a letter from Eva to her estranged husband, but its core is the mother-son standoff: Did Eva create Kevin through her coldness? Or was Kevin always a monster, using her guilt as his permission? The story refuses to answer. What remains is a devastating portrait of two people who cannot love each other—and yet are chained together forever by blood and horror. The son’s final request (for her to visit him in prison) is both a plea and a punishment.
Literature and cinema both dove headlong into Freud’s shadow, but they diverged on who holds the knife.
To understand the narrative function of the mother-son dynamic, one must look to two primary psychological frameworks often utilized by authors and directors:
1. The Freudian Oedipus Complex Sigmund Freud’s theory remains the most influential (and controversial) lens. In literature and film, this manifests as a possessive maternal love that stifles the son’s development. The son feels a subconscious romantic rivalry with the father and an inability to detach from the mother. real indian mom son mms link
2. The Object Relations Theory (D.W. Winnicott) This theory focuses on the "good enough mother"—one who allows the child to transition from total dependence to independence. In modern narratives, we often see the failure of this transition. The mother refuses to let the son "separate," resulting in a "debt" the son can never repay.
Of all the bonds explored in art, few are as primal, complex, and enduring as that between mother and son. It is a relationship forged in absolute dependence, tempered by the struggle for independence, and often haunted by unspoken expectations. In cinema and literature, this dynamic becomes a powerful lens through which we examine love, guilt, ambition, trauma, and the very definition of self.
In its earliest and most idealized form, the mother-son relationship is a sanctuary. Literature offers figures like Marmee March in Louisa May Alcott’s Little Women, a moral and emotional compass for her sons (and daughters), representing unconditional nurture. In cinema, the stoic, land-poor mothers of John Ford’s Westerns or the fierce protectors in films like The Pursuit of Happyness portray the mother as a shield against a cruel world. Here, the son’s journey is often one of grateful emulation—learning strength, resilience, and compassion from the first woman he ever knew. Eva Khatchadourian never wanted to be a mother
But art soon complicates this portrait. The mother can also be a source of profound conflict, a figure whose love smothers as much as it shelters. Think of the monstrous maternal archetypes: from the possessive, delusional Madame Bovary, whose romantic disappointments warp her love for her daughter (note: but with a son, the dynamic shifts toward vicarious ambition), to the ultimate literary symbol, Hamlet’s Gertrude. Shakespeare crafts a son paralyzed by his mother’s perceived betrayal, turning familial love into a riddle of lust, power, and revenge. Cinema gives us the corrosive mother-son relationships in Precious and The Sopranos (Livia Soprano), where maternal cruelty or emotional manipulation becomes a lifelong prison for the son.
The 20th century saw this relationship dissected with psychological precision. D.H. Lawrence’s Sons and Lovers is perhaps the ur-text: a mother who, disappointed by her husband, pours all her intellectual and emotional energy into her sons, crippling their ability to form adult romantic bonds. This “devouring mother” archetype found its cinematic peak in Hitchcock’s Psycho, where Norman Bates’s relationship with his mother is literally a matter of life, death, and split identity. Here, the thread that binds becomes a noose.
Yet, contemporary stories have moved toward reconciliation and nuance. They ask: what happens when the son becomes the caretaker? In Cormac McCarthy’s The Road, the father-son duo is central, but it is the memory of the mother—her absence, her despair—that haunts their journey. Conversely, films like The King’s Speech show a son (King George VI) striving to earn the respect of a distant, duty-bound mother figure. More recently, Marriage Story and Eighth Grade explore modern, often tenderly awkward mother-son dynamics, where communication is flawed but love is palpable. The son is no longer just an extension of her will, but a distinct, complex individual whose separation is not a betrayal, but a completion of her work. Common in working-class literature and cinema, this dynamic
Ultimately, the mother-son relationship in art mirrors our deepest human paradox: the need to be held and the need to be free. Literature gives us the interior monologue of a son’s resentment and a mother’s silent sacrifice. Cinema gives us the unspoken glance across a crowded room, the harsh word that lingers for decades, the final embrace that heals nothing yet means everything. Whether a source of strength or a wound that never closes, this thread—unbreakable, tangled, and alive—remains one of storytelling’s most resonant and essential chords.
Common in working-class literature and cinema, this dynamic features a mother who sacrifices everything for the son’s upward mobility. The son carries the heavy burden of "repaying" her suffering.
Sethe, an escaped slave, kills her infant daughter rather than let her be captured into slavery. The ghost of that daughter—Beloved—returns as a young woman to consume Sethe’s adult son, Denver, and to possess Sethe herself. Here, the mother-son relationship is refracted through trauma: Sethe’s surviving son, Howard, flees the haunted house early. The story becomes a meditation on a mother’s love so absolute it becomes murder—and the sons who can only survive by running away. Morrison’s insight: slavery weaponizes motherhood. A mother’s choice to kill is a mother’s choice to own her child’s death. The son’s escape is not betrayal; it’s the only sane response.
Most of the Coders' Manual is devoted to explaining how to make decisions about the tags. This is extremely valuable information if you decide to study the tags for scientific purposes, because the instructions provide insights into what the tags mean and how the annotators made decisions.
Utterance objects have methods for accessing the POS-tagged version of the utterance as a plain string, and as a list of (string, tag) tuples. In addition, optional parameters to the methods allow you to regularize the words and tags in various ways:
utt.pos() gives you the raw string of the POS version:
You can use utt.text_words() to break the raw text on whitespace. More interesting is utt.pos_words(), which does the same for the POS-tagged version, which is often simpler, in that it lacks disfluency markers and information about the nature of the turn.
The option wn_lemmatize=True runs the WordNet lemmatizer:
pos_lemmas() has the same options as pos_words() but it returns the (string, tag) tuples:
As far as I can tell, the alignment between the raw text and the POS tags is extremely reliable, with differences largely concerning elements that were not tagged (mostly disfluency markers and non-verbal elements).
Not all utterances have trees; only a subset of the Switchboard is fully parsed. Here's a quick count of the utterances with parsetrees:
There are 221616 utterances in all, so about 53% have trees.
The relationship between the utterances/POS and the trees is highly frought. There is no simple mapping from the original release of the corpus, or the POS version, to the trees. For the parsing, some utterances were merged together into single trees, others were split across trees, and the basic numbering was changed, often dramatically. I myself did the text–POS–tree alignments automatically (not by hand!) using a wide range of heuristic matching techniques. There are definitely lingering misalignments. (If you notice any, please send me the transcript and utterance number.)
In the example used just above, the utterance and its POS match the tree, with the non-matching material being just trace markers and disfluency tags:
Sometimes the utterance corresponds to a subtree of a given tree. In that case, utt.trees includes the entire tree, and it is important to restrict attention to the utterance's substructure when thinking about (counting elements of) the tree(s):
Here, one can imagine pulling out (FRAG (IN if) (RB not) (ADJP (JJR more))) to work with it separately from its containing tree. NLTK tree libraries have a subtrees() method that makes this easy:
The most challenging situation is where the utterance overlaps two trees, but does not correspond to either of them, or even to identifiable subtrees of them:
Here, there is no unique node that dominates right, ?, and the disfluency marker but excludes the rest of the utterance
Of course, the easiest tree structures to deal with are those that correspond exactly to the utterance itself. The Utterance method tree_is_perfect_match() allows you to pick out just those situations. It does this by heuristically matching the raw-text terminals with the leaves of the tree structure. The following function counts the number of such utterances:
The output of the above is 96370 (0.829738688708 percent). This suggests that, when studying the trees, we can limit attention to matching-tree subset. However, we should first look to make sure that the overall distribution of tags is the same for this subset; it is conceivable that a specific tag never gets its own tree and thus would appear less in this subset.
Figure PERCOMPARE compares the percentages in Table DAMSL with the percentages from the restricted subset that that have full-tree matches. The distributions looks largely the same, suggesting that work involving parsetrees can limit attention to the matching-tree subset. However, if an analysis focuses on a specific subset of the tags, then more careful comparison is advised. (For example, x (non-verbal) and ^g (tag-questions) seem to be quite different from this perspective: non-verbal utterances are typically not parsed at all, and tag-questions are often treated as their own dialogue act but merged with the preceding tree when parsed.)
exercise ROOTS, exercise POS, exercise TAGS
SAMPLE Pick a transcript at random and study it a bit, to get a sense for what the data are like. Some things you might informally assess:
META The following code skeleton loops through the transcripts, creating an opportunity to count pieces of meta-data at that level. Complete the code by counting two different pieces of meta-data. Submit both the code and its output as your answer.
Advanced extension: allow the user to supply a Transcript attribute as the argument to the function, and then use that attribute inside the loop, to compile its cont distribution.
ROOTS The following skeletal code loops through the utterances, creating an opportunity to counts utterance-level information.
POSThis question compares heavily edited newspaper text with naturalistic dialogue by looking at the distribution of POS tags in two such resources.
TAGS How are tag questions parsed? Choose one of the following two methods for addressing this:
Home
 This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License.
This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License.